Ce problème nécessite un score z ou un score standard, qui prendra en compte la moyenne historique, comme d'autres personnes l'ont mentionné, mais aussi l'écart type de ces données historiques, ce qui le rend plus robuste que la simple utilisation de la moyenne.
Dans votre cas, un z-score est calculé par la formule suivante, où la tendance serait un taux tel que les vues / jour.
z-score = ([current trend] - [average historic trends]) / [standard deviation of historic trends]
Lorsqu'un z-score est utilisé, plus le z-score est élevé ou faible, plus la tendance est anormale. Par exemple, si le z-score est très positif, la tendance est anormalement ascendante, tandis que s'il est très négatif, elle est anormalement descendante. Ainsi, une fois que vous aurez calculé le z-score de toutes les tendances candidates, les 10 z-scores les plus élevés seront liés aux z-scores les plus anormalement croissants.
Veuillez consulter Wikipedia pour plus d'informations, sur les z-scores.
Code
from math import sqrt
def zscore(obs, pop):
# Size of population.
number = float(len(pop))
# Average population value.
avg = sum(pop) / number
# Standard deviation of population.
std = sqrt(sum(((c - avg) ** 2) for c in pop) / number)
# Zscore Calculation.
return (obs - avg) / std
Exemple de sortie
>>> zscore(12, [2, 4, 4, 4, 5, 5, 7, 9])
3.5
>>> zscore(20, [21, 22, 19, 18, 17, 22, 20, 20])
0.0739221270955
>>> zscore(20, [21, 22, 19, 18, 17, 22, 20, 20, 1, 2, 3, 1, 2, 1, 0, 1])
1.00303599234
>>> zscore(2, [21, 22, 19, 18, 17, 22, 20, 20, 1, 2, 3, 1, 2, 1, 0, 1])
-0.922793112954
>>> zscore(9, [1, 2, 0, 3, 1, 3, 1, 2, 9, 8, 7, 10, 9, 5, 2, 4, 1, 1, 0])
1.65291949506
Notes
-
Vous pouvez utiliser cette méthode avec une fenêtre glissante (c'est-à-dire les 30 derniers jours) si vous souhaitez ne pas prendre en compte trop d'historique, ce qui rendra les tendances à court terme plus prononcées et peut réduire le temps de traitement.
-
Vous pouvez également utiliser un z-score pour des valeurs telles que le changement de vues d'un jour à l'autre pour localiser les valeurs anormales d'augmentation/diminution des vues par jour. Cela revient à utiliser la pente ou la dérivée du graphique des vues par jour.
-
Si vous gardez la trace de la taille actuelle de la population, du total actuel de la population et du total actuel de x^2 de la population, vous n'avez pas besoin de recalculer ces valeurs, seulement de les mettre à jour et donc vous n'avez besoin de garder ces valeurs que pour l'historique, pas chaque valeur de données. Le code suivant en fait la démonstration.
from math import sqrt
class zscore:
def __init__(self, pop = []):
self.number = float(len(pop))
self.total = sum(pop)
self.sqrTotal = sum(x ** 2 for x in pop)
def update(self, value):
self.number += 1.0
self.total += value
self.sqrTotal += value ** 2
def avg(self):
return self.total / self.number
def std(self):
return sqrt((self.sqrTotal / self.number) - self.avg() ** 2)
def score(self, obs):
return (obs - self.avg()) / self.std()
-
En utilisant cette méthode, votre flux de travail serait le suivant. Pour chaque sujet, étiquette ou page, créez un champ à virgule flottante pour le nombre total de jours, la somme des vues et la somme des vues au carré dans votre base de données. Si vous disposez de données historiques, initialisez ces champs en utilisant ces données, sinon initialisez-les à zéro. À la fin de chaque journée, calculez le score z en utilisant le nombre de vues de la journée par rapport aux données historiques stockées dans les trois champs de la base de données. Les sujets, les tags ou les pages présentant les X z-scores les plus élevés sont vos X "tendances les plus chaudes" du jour. Enfin, mettez à jour chacun des trois champs avec la valeur du jour et répétez le processus le jour suivant.
Nouvel ajout
Les z-scores normaux, comme nous l'avons vu plus haut, ne tiennent pas compte de l'ordre des données et, par conséquent, le z-score pour une observation de '1' ou de '9' aurait la même magnitude par rapport à la séquence [1, 1, 1, 1, 9, 9, 9, 9]. Il est évident que pour la recherche de tendances, les données les plus récentes devraient avoir plus de poids que les données plus anciennes et nous voulons donc que l'observation '1' ait un score de magnitude plus élevé que l'observation '9'. Pour y parvenir, je propose un z-score moyen flottant. Il convient de préciser que cette méthode n'est PAS garantie comme étant statistiquement valable, mais qu'elle devrait être utile pour la recherche de tendances ou autres. La principale différence entre le z-score standard et le z-score moyen flottant est l'utilisation d'une moyenne flottante pour calculer la valeur moyenne de la population et la valeur moyenne de la population au carré. Voir le code pour plus de détails :
Code
class fazscore:
def __init__(self, decay, pop = []):
self.sqrAvg = self.avg = 0
# The rate at which the historic data's effect will diminish.
self.decay = decay
for x in pop: self.update(x)
def update(self, value):
# Set initial averages to the first value in the sequence.
if self.avg == 0 and self.sqrAvg == 0:
self.avg = float(value)
self.sqrAvg = float((value ** 2))
# Calculate the average of the rest of the values using a
# floating average.
else:
self.avg = self.avg * self.decay + value * (1 - self.decay)
self.sqrAvg = self.sqrAvg * self.decay + (value ** 2) * (1 - self.decay)
return self
def std(self):
# Somewhat ad-hoc standard deviation calculation.
return sqrt(self.sqrAvg - self.avg ** 2)
def score(self, obs):
if self.std() == 0: return (obs - self.avg) * float("infinity")
else: return (obs - self.avg) / self.std()
Exemple IO
>>> fazscore(0.8, [1, 1, 1, 1, 1, 1, 9, 9, 9, 9, 9, 9]).score(1)
-1.67770595327
>>> fazscore(0.8, [1, 1, 1, 1, 1, 1, 9, 9, 9, 9, 9, 9]).score(9)
0.596052006642
>>> fazscore(0.9, [2, 4, 4, 4, 5, 5, 7, 9]).score(12)
3.46442230724
>>> fazscore(0.9, [2, 4, 4, 4, 5, 5, 7, 9]).score(22)
7.7773245459
>>> fazscore(0.9, [21, 22, 19, 18, 17, 22, 20, 20]).score(20)
-0.24633160155
>>> fazscore(0.9, [21, 22, 19, 18, 17, 22, 20, 20, 1, 2, 3, 1, 2, 1, 0, 1]).score(20)
1.1069362749
>>> fazscore(0.9, [21, 22, 19, 18, 17, 22, 20, 20, 1, 2, 3, 1, 2, 1, 0, 1]).score(2)
-0.786764452966
>>> fazscore(0.9, [1, 2, 0, 3, 1, 3, 1, 2, 9, 8, 7, 10, 9, 5, 2, 4, 1, 1, 0]).score(9)
1.82262469243
>>> fazscore(0.8, [40] * 200).score(1)
-inf
Mise à jour
Comme David Kemp l'a fait remarquer à juste titre, si l'on donne une série de valeurs constantes et que l'on demande ensuite un zscore pour une valeur observée qui diffère des autres valeurs, le résultat devrait probablement être différent de zéro. En fait, la valeur renvoyée devrait être l'infini. J'ai donc modifié cette ligne,
if self.std() == 0: return 0
à :
if self.std() == 0: return (obs - self.avg) * float("infinity")
Ce changement est reflété dans le code de la solution fazscore. Si l'on ne veut pas traiter les valeurs infinies, une solution acceptable pourrait être de remplacer la ligne par :
if self.std() == 0: return obs - self.avg



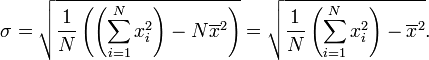{kind=link}
0 votes
C'est exactement ce que Topix.com doit faire. La question connexe ne donne aucune code mais il donne définitivement une algorithme . Utilisez l'algorithme de Demaine, cité vers le bas de la page 4 de l'article, pour calculer les dix premières recherches (ou plus) à partir d'un journal des dernières 24 heures. Si vous voulez les classer, vous devez repasser le journal en boucle et compter les occurrences de chaque recherche. C'est un article long et plutôt technique, mais il contient en fait les informations dont vous avez besoin pour traiter les sujets les plus chauds de manière évolutive.
0 votes
Topix.com doit donc utiliser l'algorithme majoritaire ? L'approche suivante est-elle correcte ? paste.bradleygill.com/index.php?paste_id=9117
0 votes
En utilisant l'algorithme de Demaine, trouvez-vous vraiment les sujets les plus chauds ? Ou le résultat sera-t-il les sujets qui sont toujours d'actualité (Britney Spears, la météo, ...) ?
0 votes
Veuillez me donner plus de réponses ! Mon problème n'est pas encore résolu et je devrais choisir une réponse pour la prime bientôt.
1 votes
C'est exactement la même question et il le dit même ! Pourquoi les gens votent-ils en faveur de ce texte ?
0 votes
Eh, c'est pile ou face. Celui-ci demande spécifiquement un code. En dehors de cela, ils sont essentiellement les mêmes.
3 votes
Je suis un peu confus quant au type de résultat que vous recherchez. L'article semble indiquer que "Britney Spears" figurera systématiquement dans la liste "Hot" parce que de nombreuses personnes recherchent ce terme, mais votre question indique qu'il n'apparaîtra PAS dans la liste parce que le nombre de recherches pour ce terme n'augmente pas beaucoup au fil du temps (il reste élevé, mais stable). Quel résultat cherchez-vous à obtenir ? Le terme "Britney Spears" doit-il être classé haut ou bas ?
0 votes
@Adam - On lui a proposé plusieurs options différentes en pseudo-code dans l'autre question, mais il les a rejetées parce qu'il ne les comprenait pas. On dirait qu'il veut la solution sur un plateau d'argent, et non une stratégie ou un algorithme pour résoudre le problème.
1 votes
@eJames, "Britney Spears" ne devrait pas être bien classé parce qu'elle est constamment un terme de recherche élevé et qu'il recherche des termes de recherche avec une vitesse élevée.
0 votes
@James - Eh bien, parmi les suggestions fournies, une seule a donné un indice d'un algorithme qui écarte les sujets perpétuellement chauds, mais attrape les sujets anormalement chauds - le gradient. Malheureusement, avec des milliers de sujets par heure, le gradient ne peut pas s'adapter. Il aurait peut-être mieux valu qu'il mette à jour la question avec des informations plus pertinentes, mais cette version contient également des informations raisonnablement bonnes. Je suis partial, ayant passé un peu de temps à répondre à sa question, mais entre les deux, laquelle est la meilleure ? S'il s'agit de doublons, il faut fermer celui qui est le plus mauvais, et non le plus récent.
0 votes
@Adam Davis- Je suis d'accord, l'autre devrait être fermé.
0 votes
@Simucal : Exactement, c'est ce que j'aimerais réaliser. @James Van Huis : Désolé, mais ce n'est pas correct. Il n'y avait qu'une seule réponse avec un pseudo code. Et je ne peux pas l'utiliser pour mon objectif. @ALL : Dans cette question, j'ai décrit mon problème beaucoup mieux, je pense. Donc, il y a encore de meilleures réponses ici. Elle ne devrait pas être fermée ! @Adam Davis : Merci pour votre réponse ! Celle-ci et toutes les autres sont bien meilleures que celles à l'autre question. Donc - si possible - fermez l'autre question, s'il vous plaît.
0 votes
Vous avez peut-être oublié que SO a cette même capacité sur la page principale. Je dis ça comme ça... ;-)
1 votes
Vote pour la réouverture : Il s'agit d'une question de suivi de la question initiale, portant sur un problème particulier qui se pose lorsqu'on essaie de résoudre le problème initial.
1 votes
Pas une réplique exacte, pas même une quasi-réplique. Cette question porte sur la résolution d'un problème spécifique avec un algorithme spécifique.
0 votes
Je ne pense pas non plus que ce soit un doublon. C'est dommage que les deux questions aient été combinées. Les réponses aux deuxièmes questions étaient bien meilleures mais je ne peux plus les choisir comme la meilleure réponse.
0 votes
Woah, saintes questions de fusion, Batman ! Maintenant, je ne suis plus au sommet parce que la question à laquelle j'ai répondu a été fusionnée avec une question dont la réponse était déjà acceptée. Bizarre...
0 votes
Oui, c'est vraiment bizarre. J'aimerais choisir une autre réponse comme étant la meilleure. Mais ça ne semble pas être possible.
0 votes
La méthode du Z-score ne fonctionnerait pas bien si le nombre de mots-clés (ou de sujets) est faible. Dans ce cas, je recommanderais de modéliser le problème comme une distribution de Poisson.