
J'ai donc vu cette question et était curieux de savoir ce que le Lemme de Pompage a été (Wikipédia n'est pas beaucoup d'aide). Je comprends que c'est en fait théorique de preuve qui doivent être remplies pour qu'une langue soit dans une certaine classe, mais au-delà de que je n'ai pas vraiment l'obtenir. Quelqu'un veut bien essayer de l'expliquer à une assez précise d'une manière compréhensible par des non mathématiciens/comp sci doctorats?
Réponses
Trop de publicités?
Graphics Noob
Points
4004
L'on a accepté la réponse est bonne, mais je n'ai pas envie qu'il explique le but de le lemme de pompage.
Le lemme de pompage est une preuve simple de montrer qu'une langue n'est pas régulier, ce qui signifie qu'une Machine à État Fini ne peut être construit pour elle. L'exemple canonique est la langue (a^n)(b^n). C'est le langage simple qui est juste n'importe quel nombre de as, suivie par le même nombre de bs. Afin que les chaînes
ab
aabb
aaabbb
aaaabbbb
etc. sont dans la langue, mais
aab
bab
aaabbbbbb
etc. ne le sont pas.
Il est assez simple de construire un FSM pour ces exemples:

Celui-ci fonctionnera tout le chemin jusqu'à n=4. Le problème est que notre langue n'a pas mis toute contrainte sur n, et des Machines à états Finis doivent être, bien finie. Peu importe la façon dont beaucoup de membres je ajouter à cette machine, quelqu'un peut me donner une entrée où n est égal au nombre de membres plus un et ma machine va échouer. Donc si il y a peut être une machine conçue pour lire cette langue, il doit y avoir une boucle quelque part là-bas pour garder le nombre d'états finis. Avec ces boucles ajouté:
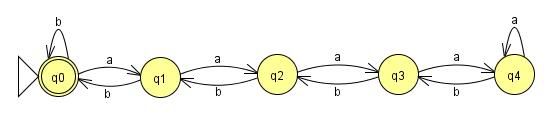
toutes les chaînes dans notre langue sera accepté, mais il y a un problème. Après les quatre premiers as, la machine perd le compte de combien de as ont été d'entrée, parce qu'il reste dans le même état. Cela signifie que, après quatre, je peux ajouter autant d' as que je veux à la chaîne, sans ajout de bs, et toujours obtenir la même valeur de retour. Cela signifie que les chaînes de caractères:
aaaa(a*)bbbb
avec (a*) représentant le nombre de as, tout le monde sera accepté par la machine, même si elles ne sont évidemment pas tous dans la langue. Dans ce contexte, nous pouvons dire que la partie de la chaîne (a*) peut être pompé. Le fait que la Machine à État Fini est fini et n n'est pas bornée, garantit que n'importe quelle machine qui accepte toutes les chaînes dans la langue DOIT avoir cette propriété. La machine doit en boucle à un certain point, et au point qu'elle boucle la langue peut être pompé. Donc pas de Machine à états Finis peut être construit pour cette langue, et la langue n'est pas régulière.
Rappelez-vous que les Expressions Régulières et des Machines à états Finis sont équivalentes, puis replacez - a et b avec l'ouverture et la fermeture des balises Html qui peut être incorporé à l'intérieur les uns des autres, et vous pouvez voir pourquoi il n'est pas possible d'utiliser des expressions régulières pour analyser Html
Comme d'autres l'ont souligné, cette réponse est partiellement incorrecte et la plus haute cote de réponse doit être accepté de répondre.
Effectivement un lemme de pompage états que l'on peut insérer des chaînes arbitraires (autorisé dans la langue) et de ne pas parvenir à une conclusion.
Autrement dit, un mot peut être "pompé" de telle sorte que toute chaîne de caractères peut être inséré dans le milieu de la parole et la parole est toujours valide.

Ce diagramme ci-dessus, dit que je peux avoir la chaîne de [ad], [abcd], [abcbcd], [abcbcbcd], ad. infinum et je vais être dans les limites de la langue. Cela signifie un nombre infini de la colombie-britannique peuvent être insérés dans le milieu de la parole et la parole reste valide dans la langue. Ainsi, cette langue peut être pompé.
Maintenant, prenez XML, XML du langage commence et finit avec l' <xml></xml> respectivement. XML peut être pompé parce que n'importe quel ensemble de balises peut être insérée entre le tag et le XML sera acceptée XML.
Ou de prendre de flux RSS, un sous-ensemble de XML. On pourrait continuer à ajouter des éléments à un flux RSS pour toujours, et il ne serait pas accepté flux RSS et ainsi acceptée XML.
Remarque en règle, je veux dire un mot dans la langue.
David Thornley
Points
39051
C'est un appareil destiné à prouver qu'une langue donnée ne peut pas être d'une certaine classe.
Considérons la langue de l'équilibre entre parenthèses (la signification des symboles '(' et ')', et y compris toutes les chaînes qui sont en équilibre dans le sens habituel, et aucun qui ne le sont pas). On peut utiliser le lemme de pompage pour montrer que ce n'est pas régulière.
(Une langue est un ensemble de possible des chaînes de caractères. Un analyseur est une sorte de mécanisme que nous pouvons utiliser pour voir si une chaîne est dans la langue, de sorte qu'il a d'être en mesure de faire la différence entre une chaîne de caractères dans la langue ou une chaîne de caractères en dehors de la langue. Une langue est "normal" (ou "context-free" ou "sensible au contexte" ou quoi que ce soit) si il y a une (ou autre) de l'analyseur qui permet de reconnaître, de distinguer entre des chaînes de caractères dans la langue et les chaînes de caractères dans la langue.)
LFSR de Consultation a fourni une bonne description. Nous pouvons tirer un analyseur syntaxique pour un langage régulier comme une partie limitée de la collection de boîtes et de flèches, les flèches représentant des personnages et les boîtes de connexion (agissant en tant que "membres"). (Si c'est plus compliqué que cela, il n'est pas un langage régulier.) Si nous pouvons obtenir une chaîne de plus que le nombre de boîtes, cela signifie que nous sommes allés à travers une zone plus d'une fois. Cela signifie que nous avons eu une boucle, et nous pouvons passer à travers la boucle autant de fois que nous voulons.
Donc, pour un langage régulier, si nous pouvons créer arbitrairement une longue chaîne de caractères, on peut le diviser en xyz, où x est le personnages nous avons besoin pour obtenir le début de la boucle, y est la boucle, et z est ce dont nous avons besoin pour rendre la chaîne valide après la boucle. L'important, c'est que le total des longueurs de x et de y sont limitées. Après tout, si la longueur est plus grande que le nombre de boîtes, nous avons évidemment passé par une autre boîte en faisant cela, et donc il y a une boucle.
Ainsi, dans notre équilibrée de la langue, on peut commencer par écrire n'importe quel nombre de parenthèses gauche. En particulier, pour n'importe quel analyseur de donnée, on peut écrire plus de gauche, de parens qu'il ya des boîtes, et donc l'analyseur ne peut pas dire combien de gauche parens. Donc, x est un montant de gauche parens, et ce n'est fixé. y est également un certain nombre de gauche parens, et cela peut augmenter indéfiniment. On peut dire que z est un nombre de droit parens.
Cela signifie que nous pourrions avoir une chaîne de 43 à gauche parens et 43 droit des parens reconnu par notre analyseur, mais l'analyseur ne peut pas dire qu'à partir d'une chaîne de 44 à gauche parens et 43 droit des parens, qui n'est pas dans notre langue, de sorte que l'analyseur ne peut pas analyser notre langue.
Depuis tout possible régulier de l'analyseur dispose d'un nombre fixe de cases, on peut toujours écrire plus de gauche, de parens, et par le lemme de pompage ensuite, nous pouvons ajouter plus de gauche, de parens dans une manière que l'analyseur ne peut pas dire. Par conséquent, l'équilibre entre parenthèses de la langue ne peut pas être analysé par un régulier de l'analyseur, et n'est donc pas une expression régulière.
bigwoody
Points
347
Son une chose difficile à obtenir en termes simples, mais, fondamentalement, les expressions régulières doivent avoir un non vide de sous-chaîne au sein de ce que peut être répété autant de fois que vous le souhaitez tout l'ensemble de la nouvelle-mot demeure valide pour la langue.
Dans la pratique, le pompage de lemmes ne sont pas suffisantes pour PROUVER une langue correcte, mais plutôt comme un moyen de faire une preuve par contradiction et de montrer une langue ne rentre pas dans la classe de langues (Régulier ou Libre de tout Contexte) par montrer le lemme de pompage ne fonctionne pas pour elle.
starblue
Points
29696
Le simple pompage lemme est l'un pour les langages réguliers, qui sont des ensembles de chaînes de caractères décrits par des automates finis, entre autres choses. La caractéristique principale d'un nombre fini d'automatisation est qu'il ne dispose que d'une quantité limitée de mémoire, décrit par ses membres.
Maintenant, supposons que vous avez une chaîne, qui est reconnu par un automate fini, et qui est assez long à "dépasser" la mémoire de l'automatisation, c'est à dire que les états doivent répéter. Alors il existe une sous-chaîne où l'état de l'automate au début de la sous-chaîne est la même que l'état à la fin de la sous-chaîne. Depuis la lecture de la sous-chaîne ne change pas l'état, il peut être retiré ou dupliqué un nombre arbitraire de fois, sans l'automate d'être le plus sage. Donc modifié ces chaînes doivent également être acceptés.
Il y a aussi un peu plus compliqué lemme de pompage pour le contexte des langues, où vous pouvez supprimer/insérer ce qui peut intuitivement être considérés comme des parenthèses correspondantes à deux endroits dans la chaîne.

