Est-il un moyen simple pour aplatir une liste de iterables avec une compréhension de liste, ou, à défaut, que feriez-vous tous, la meilleure façon de les aplatir un peu la liste de ce genre, l'équilibrage de la performance et de la lisibilité?
J'ai essayé de les aplatir cette liste avec une liste imbriquée de compréhension, comme ceci:
[image for image in menuitem for menuitem in list_of_menuitems]
Mais j'ai des ennuis de l' NameError variété, parce que l' name 'menuitem' is not defined. Après googler et autour de la recherche sur Stack Overflow, j'ai obtenu les résultats désirés avec un reduce déclaration:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Mais cette méthode est assez illisible parce que j'ai besoin qu' list(x) appeler de là, parce que x est un Django QuerySet objet.
Conclusion:
Merci à tous ceux qui ont contribué à cette question. Voici un résumé de ce que j'ai appris. Je suis aussi ce qui en fait un wiki de la communauté dans le cas où d'autres veulent ajouter ou corriger ces observations.
Mon original de réduire déclaration est redondant et c'est mieux écrit de cette manière:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
C'est la syntaxe correcte pour une liste imbriquée compréhension (Brillant résumé dF!):
>>> [image for mi in list_of_menuitems for image in mi]
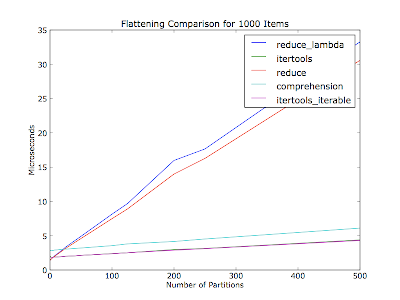
Mais aucune de ces méthodes sont aussi efficaces que les itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
Et comme @cdleary notes, c'est probablement mieux de style à éviter * l'opérateur de la magie en utilisant chain.from_iterable comme:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]