
C'est pourquoi je vous pose cette question: L'année dernière j'ai fait un peu de code C++ pour calculer les probabilités a posteriori pour un type particulier de modèle (décrit par un réseau Bayésien). Le modèle a fonctionné assez bien et quelques autres personnes ont commencé à utiliser mon logiciel. Maintenant, je veux améliorer mon modèle. Depuis que je suis déjà codage légèrement différents algorithmes d'inférence pour le nouveau modèle, j'ai décidé d'utiliser python en raison d'exécution n'était pas très important et python peuvent permettez-moi de rendre plus élégant et maniable code.
Généralement dans cette situation, je voudrais rechercher un réseau Bayésien package python, mais les algorithmes d'inférence que j'utilise sont les miennes, et j'ai aussi pensé que ce serait une excellente occasion d'en apprendre plus sur la bonne conception de python.
J'ai déjà trouvé un grand module python pour le réseau des graphes (networkx), qui permet d'attacher un dictionnaire à chaque nœud et chaque bord. Essentiellement, cela permettez-moi de vous donner des nœuds et des arêtes de propriétés.
Pour un réseau particulier et les données observées, j'ai besoin d'écrire une fonction qui calcule la probabilité de la non affecté de variables dans le modèle.
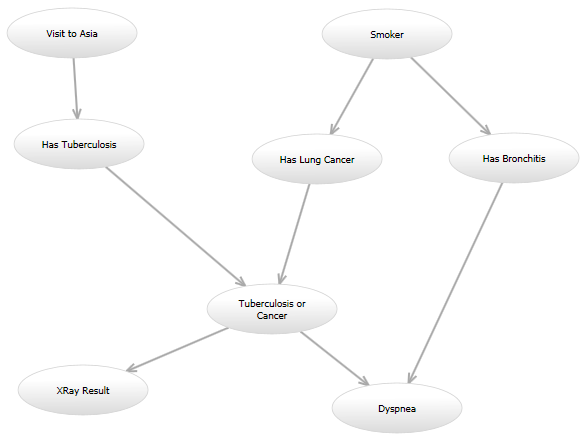
Par exemple, dans le classique "Asie" (réseauhttp://www.bayesserver.com/Resources/Images/AsiaNetwork.png), avec les états de "XRay Résultat" et "Dyspnée" connu, j'ai besoin d'écrire une fonction pour calculer la probabilité que les autres variables ont certaines valeurs (selon un certain modèle).
Voici ma programmation de la question: Je vais essayer de faire une poignée de modèles, et dans l'avenir, il est possible que je souhaite essayer un autre modèle par la suite. Par exemple, un modèle peut ressembler exactement le réseau Asie. Dans un autre modèle, un dirigé bord peut être ajouté à partir de "Visite à l'Asie" à "A un Cancer du Poumon." Un autre modèle pourrait utiliser l'original graphe orienté, mais le modèle de probabilité pour la "Dyspnée" nœud donné le "la Tuberculose ou le Cancer" et "Bronchite" nœuds peuvent être différentes. L'ensemble de ces modèles permettra de calculer la probabilité d'une façon différente.
Tous les modèles ont un chevauchement important; par exemple, plusieurs bords d'entrer dans un "Ou" nœud fera toujours un "0" si toutes les entrées sont à "0" et "1" dans le cas contraire. Mais certains modèles ont des nœuds qui prennent des valeurs entières dans une certaine gamme, tandis que d'autres devront être de type boolean.
Dans le passé, j'ai eu du mal avec la façon de programmer ce genre de choses. Je ne vais pas mentir; il y a eu une bonne quantité de copié et collé le code et j'ai parfois nécessaire pour propager les changements dans une méthode unique pour plusieurs fichiers. Cette fois, j'ai vraiment envie de passer du temps à faire de la bonne façon.
Quelques options:
- Je faisais déjà ce la bonne manière. Le premier Code, de poser des questions plus tard. Il est plus rapide de copier et de coller le code et d'avoir une classe pour chaque modèle. Le monde est un endroit sombre et la désorganisation de la place...
- Chaque modèle est sa propre classe, mais également une sous-classe d'un général BayesianNetwork modèle. Ce modèle général allons utiliser quelques fonctions qui vont être remplacées. Stroustrup serait fier.
- Faire plusieurs fonctions dans la même classe que le calcul des différentes probabilités.
- Code général BayesianNetwork de la bibliothèque et de mettre en œuvre mes inférence problèmes spécifiques des graphiques lue par cette bibliothèque. Les nœuds et les arêtes doivent être donné des propriétés comme "Booléen" et "OrFunction" qui, étant donné états connus du nœud parent, peut être utilisé pour calculer les probabilités des différents résultats. Ces chaînes de propriété, comme "OrFunction" pourrait même être utilisé pour rechercher et appeler la bonne fonction. Peut-être que dans quelques années je vais faire quelque chose de similaire à la version de 1988 de Mathematica!
Merci beaucoup pour votre aide.
Mise à jour: Orientée objet idées d'une grande aide ici (chaque nœud possède un ensemble de prédécesseur nœuds d'un certain nœud sous-type, et chaque nœud a une probabilité fonction qui calcule la probabilité d'occurrence des différents états des résultats étant donné les états de l'prédécesseur nœuds, etc.). LA PROGRAMMATION ORIENTÉE OBJET FTW!


{kind=link}