
Comment retracer le chemin d'une recherche en largeur (Breadth-First Search), comme dans l'exemple suivant :
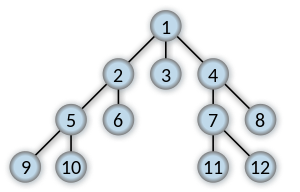
Si vous recherchez des clés 11 retourner le le plus court liste reliant 1 à 11.
[1, 4, 7, 11]Comment retracer le chemin d'une recherche en largeur (Breadth-First Search), comme dans l'exemple suivant :
Si vous recherchez des clés 11 retourner le le plus court liste reliant 1 à 11.
[1, 4, 7, 11]Vous devriez avoir regardé http://en.wikipedia.org/wiki/Breadth-first_search d'abord.
Voici une implémentation rapide, dans laquelle j'ai utilisé une liste de liste pour représenter la file d'attente des chemins.
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a
# new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')Cette empreinte : ['1', '4', '7', '11']
Une autre approche consisterait à maintenir un mappage de chaque nœud à son parent, et lors de l'inspection du nœud adjacent, à enregistrer son parent. Lorsque la recherche est terminée, il suffit de revenir en arrière en fonction du mappage du parent.
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def backtrace(parent, start, end):
path = [end]
while path[-1] != start:
path.append(parent[path[-1]])
path.reverse()
return path
def bfs(graph, start, end):
parent = {}
queue = []
queue.append(start)
while queue:
node = queue.pop(0)
if node == end:
return backtrace(parent, start, end)
for adjacent in graph.get(node, []):
if node not in queue :
parent[adjacent] = node # <<<<< record its parent
queue.append(adjacent)
print bfs(graph, '1', '11')Les codes ci-dessus sont basés sur l'hypothèse qu'il n'y a pas de cycles.
C'est excellent ! Mon processus de réflexion m'a amené à croire à la création d'un type de tableau ou de matrice, je dois encore apprendre les graphiques. Merci.
J'ai également essayé d'utiliser une approche de traçage arrière, bien que cela semble beaucoup plus propre. Serait-il possible de créer un graphe si l'on ne connaît que le début et la fin, mais pas les nœuds intermédiaires ? Ou même une autre approche que les graphes ?
Code très facile. Vous continuez à ajouter le chemin à chaque fois que vous découvrez un noeud.
graph = {
'A': set(['B', 'C']),
'B': set(['A', 'D', 'E']),
'C': set(['A', 'F']),
'D': set(['B']),
'E': set(['B', 'F']),
'F': set(['C', 'E'])
}
def retunShortestPath(graph, start, end):
queue = [(start,[start])]
visited = set()
while queue:
vertex, path = queue.pop(0)
visited.add(vertex)
for node in graph[vertex]:
if node == end:
return path + [end]
else:
if node not in visited:
visited.add(node)
queue.append((node, path + [node]))J'ai beaucoup aimé la première réponse de qiao ! La seule chose qui manque ici est de marquer les vertex comme visités.
Pourquoi devons-nous le faire ?
Imaginons qu'il existe un autre nœud numéro 13 connecté au nœud 11. Maintenant, notre objectif est de trouver le noeud 13.
Après un peu d'exécution, la file d'attente ressemblera à ceci :
[[1, 2, 6], [1, 3, 10], [1, 4, 7], [1, 4, 8], [1, 2, 5, 9], [1, 2, 5, 10]]Notez qu'il y a DEUX chemins avec le nœud numéro 10 à la fin.
Ce qui signifie que les chemins du nœud numéro 10 seront vérifiés deux fois. Dans ce cas, cela n'a pas l'air si mauvais parce que le noeud numéro 10 n'a pas d'enfants Mais cela pourrait être vraiment mauvais (même ici nous allons vérifier ce noeud deux fois sans raison )
Le nœud numéro 13 n'est pas dans ces chemins, donc le programme ne reviendra pas avant d'atteindre le deuxième chemin avec le nœud numéro 10 à la fin Et nous allons le revérifier
Tout ce qui nous manque est un ensemble pour marquer les nœuds visités et ne pas les vérifier à nouveau .
Voici le code de qiao après la modification :
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)La sortie du programme sera :
[1, 4, 7, 11, 13]Sans les revérifications intempestives
Il peut être utile d'utiliser collections.deque para queue comme list.pop(0) incur O(n) les mouvements de mémoire. De plus, pour la postérité, si vous voulez faire du DFS, définissez simplement path = queue.pop() auquel cas la variable queue agit en fait comme un stack .
Il revisitera les nœuds voisins des nœuds visités, par exemple, dans une situation avec trois nœuds 1-2-3, il visitera 1, ajoutera 2 à la file d'attente, puis ajoutera 1 et 3 à la file d'attente. Le site if vertex not in visited devrait être dans la boucle for au lieu d'être en dehors de celle-ci. Ensuite, la vérification extérieure peut être supprimée car rien ne sera ajouté à la file d'attente si le nœud a déjà été visité.
Je me suis dit que j'allais essayer de coder ça pour le plaisir :
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, forefront, end):
# assumes no cycles
next_forefront = [(node, path + ',' + node) for i, path in forefront if i in graph for node in graph[i]]
for node,path in next_forefront:
if node==end:
return path
else:
return bfs(graph,next_forefront,end)
print bfs(graph,[('1','1')],'11')
# >>>
# 1, 4, 7, 11Si vous voulez des cycles, vous pouvez ajouter ceci :
for i, j in for_front: # allow cycles, add this code
if i in graph:
del graph[i]J'aime à la fois la première réponse de @Qiao et l'ajout de @Or. Pour un souci d'un peu moins de traitement, je voudrais ajouter à la réponse de Or.
Dans la réponse de @Or, garder la trace des nœuds visités est très bien. Nous pouvons également permettre au programme de sortir plus tôt qu'il ne le fait actuellement. A un moment donné dans la boucle for, la fonction current_neighbour devra être le end et une fois que cela se produit, le chemin le plus court est trouvé et le programme peut revenir.
Je modifierais la méthode comme suit, en faisant attention à la boucle for.
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
#No need to visit other neighbour. Return at once
if current_neighbour == end
return new_path;
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)La sortie et tout le reste seront les mêmes. Cependant, le code prendra moins de temps à traiter. Ceci est particulièrement utile pour les graphiques de grande taille. J'espère que cela aidera quelqu'un à l'avenir.
Prograide est une communauté de développeurs qui cherche à élargir la connaissance de la programmation au-delà de l'anglais.
Pour cela nous avons les plus grands doutes résolus en français et vous pouvez aussi poser vos propres questions ou résoudre celles des autres.


7 votes
C'était en fait un vieux devoir sur lequel j'aidais un ami il y a quelques mois, basé sur la loi Kevin Bacon. Ma solution finale était très bâclée, j'ai essentiellement effectué une autre recherche en largeur pour revenir en arrière et faire marche arrière. Je veux trouver une meilleure solution.
25 votes
Excellent. Je considère que revisiter un vieux problème dans le but de trouver une meilleure réponse est un trait admirable chez un ingénieur. Je vous souhaite bonne chance dans vos études et votre carrière.
3 votes
Merci pour les éloges, je crois simplement que si je ne l'apprends pas maintenant, je serai à nouveau confronté au même problème.
0 votes
Duplicata possible de Comment obtenir le chemin entre 2 nœuds en utilisant la recherche en largeur (Breadth-First Search) ?