Une récente question, si les compilateurs sont autorisés à remplacer division flottante avec multiplication en virgule flottante, m'a poussé à poser cette question.
En vertu de l'exigence stricte, que les résultats obtenus après transformation du code est binaire identique à l'actuelle opération de division,
il est trivial de voir que pour les binaires IEEE-754 arithmétique, il est possible pour les diviseurs d'une puissance de deux. Tant que la réciproque
de le diviseur est représentable, en multipliant par l'inverse du diviseur donne des résultats identiques à la division. Par exemple, la multiplication par 0.5 peut remplacer la division par 2.0.
On se demande alors pour quelle autre diviseurs de tels remplacements de travail, en supposant que nous permettent de tout de courtes séquences d'instructions qui remplace la division, mais est significativement plus rapide, tout en offrant des bits des résultats identiques. En particulier permettre fused multiply-add opérations en plus de la simple multiplication. Dans les commentaires je l'ai fait à la suite des papier:
Nicolas Brisebarre, Jean-Michel Muller, et Saurabh Kumar Raina. L'accélération arrondie division flottante lorsque le diviseur est connu à l'avance. IEEE Transactions sur les Ordinateurs, Vol. 53, n ° 8, août 2004, pp. 1069-1072.
La technique préconisée par les auteurs de l'article précalcule la réciproque du diviseur de y comme un normalisée tête-queue paire zh:zl comme suit: zh = 1 / y, zl = fma (y, z,h, 1) / y. Plus tard, la division de q = x / y est calculée comme q = fma (z,h, x, zl * x). Le papier provient de diverses conditions qui diviseur de y doit satisfaire pour que cet algorithme fonctionne. Que l'on observe facilement, cet algorithme a des problèmes avec les infinis et zéro lorsque les premiers signes de la tête et la queue diffèrent. Plus important encore, il ne parvient pas à fournir des résultats corrects pour les dividendes x qui sont de très faible ampleur, car le calcul du quotient de la queue, zl * x, souffre de dépassement de capacité.
Le document fait également le passage d'une référence à un autre FMA-division basée sur l'algorithme, mis au point par Peter Markstein, quand il était à IBM. La référence pertinente est:
P. W. Markstein. Calcul de fonctions élémentaires sur les IBM RISC System/6000 processeur. IBM Journal de Recherche & Développement, Vol. 34, N ° 1, janvier 1990, pp. 111-119
Dans Markstein de l'algorithme, on calcule une réciproque rc, à partir de laquelle un premier quotient q = x * rc est formé. Ensuite, le reste de la division est calculée avec précision avec un FMA comme r = fma (-y, q, x), et une amélioration de plus justes, plus le quotient est enfin calculée comme q = fma (r, rc, q).
Cet algorithme a aussi des problèmes de x qui sont des zéros ou des infinis (facilement avec approprié de l'exécution conditionnelle), mais des tests exhaustifs à l'aide de la norme IEEE-754 simple précision float des données montre qu'il fournit la bonne quotient dans tous les possibe dividendes x pour de nombreux diviseurs y, parmi ces nombreux petits nombres. Ce code C la met en œuvre:
/* precompute reciprocal */
rc = 1.0f / y;
/* compute quotient q=x/y */
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
Sur la plupart des architectures de processeur, cela devrait se traduire par une dépourvu de branches séquence d'instructions, en utilisant soit la prédication, à condition de déplacements, ou sélectionnez-le type d'instructions. Pour donner un exemple concret: Pour la division par 3.0f, l' nvcc compilateur CUDA 7.5 génère les éléments suivants du code machine pour un Kepler GPU:
LDG.E R5, [R2]; // load x
FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF
FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f)
FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF)
FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x);
MOV R4, R2 // q
@P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q)
ST.E [R6], R4; // store q
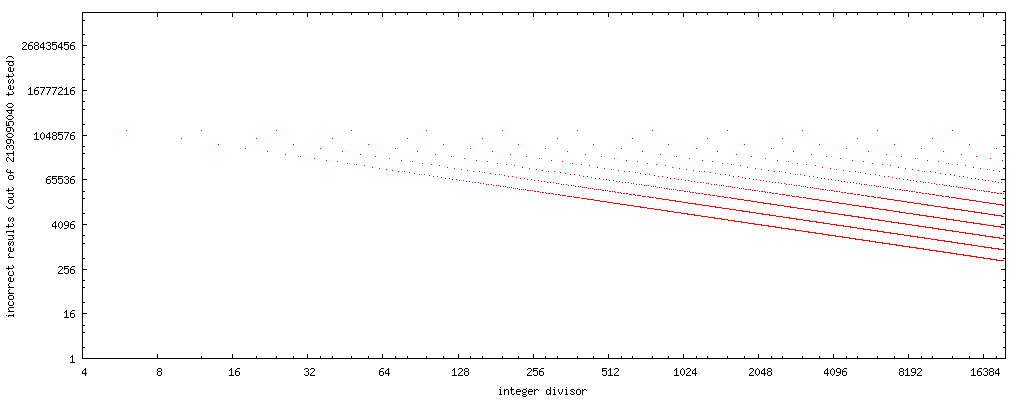
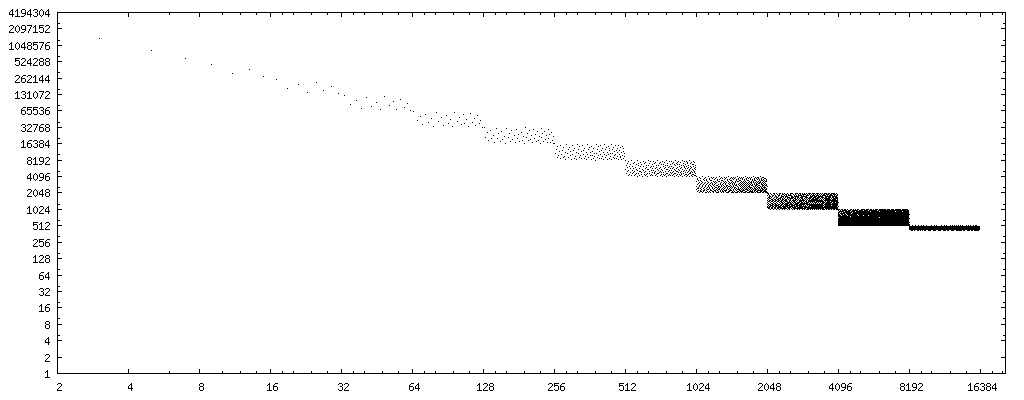
Pour mes expériences, j'ai écrit le petit C test de programme ci-dessous les étapes à travers entier diviseurs dans l'ordre croissant et pour chacun d'eux de manière exhaustive les tests ci-dessus séquence de code à l'encontre de la bonne division. Il imprime une liste des diviseurs que passé ce test exhaustif. Sortie partielle se présente comme suit:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
Pour intégrer l'algorithme de remplacement dans un compilateur comme une optimisation, une liste de diviseurs à laquelle le code ci-dessus de transformation peuvent être utilisées sans danger n'est pas pratique. La sortie du programme jusqu'à présent (à un taux d'environ un résultat par minute) suggère que le jeûne code fonctionne correctement dans tous les encodages possibles de l' x pour ceux diviseurs y qui sont des entiers impairs ou sont des puissances de deux. Les preuves anecdotiques, pas une preuve, bien sûr.
Quel ensemble de conditions mathématiques peut déterminer a priori si la transformation de la division dans le code ci-dessus, la séquence est sûr? Réponses peut supposer que toutes les opérations à virgule flottante sont effectuées dans le mode d'arrondi par défaut de "tour la plus proche, ou encore".
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main (void)
{
float r, q, x, y, rc;
volatile union {
float f;
unsigned int i;
} arg, res, ref;
int err;
y = 1.0f;
printf ("PASS: ");
while (1) {
/* precompute reciprocal */
rc = 1.0f / y;
arg.i = 0x80000000;
err = 0;
do {
/* do the division, fast */
x = arg.f;
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
res.f = q;
/* compute the reference, slowly */
ref.f = x / y;
if (res.i != ref.i) {
err = 1;
break;
}
arg.i--;
} while (arg.i != 0x80000000);
if (!err) printf ("%g, ", y);
y += 1.0f;
}
return EXIT_SUCCESS;
}